Kako sam napravio NL2SQL sistem koji ne halucinira i košta $0.002 po upitu
Hibridni pristup koji kombinuje SQL šablone, API-je, embeddings i LLM za pravljenje virtualnog asistenta koji razume prirodan jezik i generiše pouzdane SQL upite.

Kada spomenem ljudima da radim na virtualnom asistentu, njihov pogled obično kaže: “Evo ga ovaj što će da napravi program koji uzima ljudima posao”. A istina je mnogo manje dramatičnija: pravim pametan sistem, a ne “svemoguć” model. Ovaj tekst je upravo o tom sistemu, hibridu između praistorijskih regex šablona i “spakuj sve u prompt i pozovi API”.
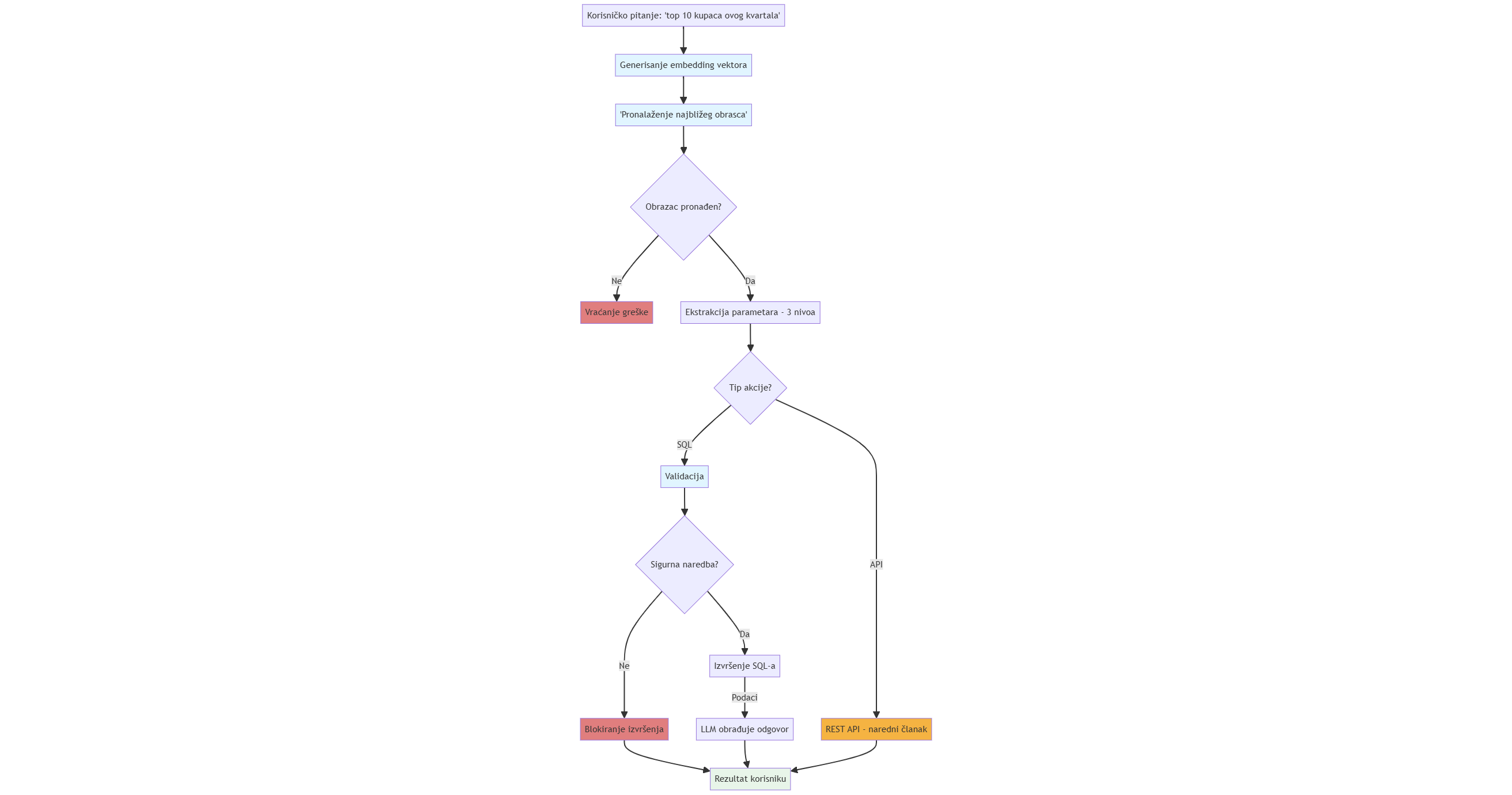
Slika: Dijagram toka hibridnog NL2SQL sistema. Od korisničkog pitanja do odgovora ili akcije.
Klikni na sliku i zumiraj
Ideja je da konceptualno objasnim strukturu projekta, koji na osnovu prirodnog i ljudskog pitanja izvršava naredbe i odgovara. I to služeći se internom bazom podataka. Sve to sam naučio za šest meseci bakćajući se sa NLP-om, embeddings-ima, LLM-ovima, halucinacijama… i jednim modelom koji se ponekad ponaša kao da je na rekreativnoj LSD dozi.
Problem: Svako želi da priča sa svojom bazom, ali niko ne priča SQL
Zamislite da prodajete građevinski materijal širom EU i imate jednu veliku, centralnu bazu podataka. Vaš prodajni tim pita “Ko su naši top 10 kupci ovog kvartala?”. Ovo je razumno pitanje. Međutim vaša baza podataka govori drugačijim jezikom:
1
2
3
4
5
6
7
8
9
SELECT
customer_name,
SUM(order_total) as total_revenue
FROM orders o
JOIN customers c ON o.customer_id = c.id
WHERE order_date >= DATE_TRUNC('quarter', CURRENT_DATE)
GROUP BY customer_name
ORDER BY total_revenue DESC
LIMIT 10;
Ta razlika između ljudskog jezika i SQL jezika je bila začkoljica koju sam želeo da premostim.
Tri dežurna krivca, i kako sam izabrao pogrešnog
Iako sam tek na početku svoje profesionalne karijere, imao sam puno prilika da čujem od predstavnika kompanija da žele da razviju i integrišu pametnog asistenta u svoj sistem. Pametni asistent bi imao svrhu da (1) razume želju korisnika, (2) dostavi informacije na osnovu podataka kompanije i (3) izvrši akciju koju korisnik zahteva. Zašto ne bih razvio virtualnog asistenta koji će sve ovo ispuniti?
Stičem utisak da za implementaciju virtualnog asistenta industrija uporno bira pogrešan alat. Ukoliko posegnete za pametnijim rešenjem od cimanja ortaka za rukav i pretvaranju da je on vaš virtualni asistent (ali sa Slack-a), pašće vam na pamet jedna od tri opcije:
Opcija 1: Regex pravila
1
2
3
4
{
"pattern": r"(dad?|hoću|prikaži).*(narudžbine|porudžbine).*(korisnika|usera) (\d+)",
"sql": "SELECT * FROM orders WHERE user_id = {user_id};"
}
“Samo koristi regex! Mapiraj ključne reči u SQL delove. Šta bi moglo da pođe po zlu?”
Sve. Sve bi moglo poći po zlu. Završio bih sa 10,000 linija unutar switch upita, tj. if grana, i jedino mi preostaje da se molim da niko nikada ne pita drugačije pitanje.
Opcija 2: Čist LLM – kinda overused nowadays
“LLM-ovi razumeju čovekov jezik! Samo prosledi u prompt DB šemu i napisaće ti SQL”
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
from openai import OpenAI
client = OpenAI()
DB_SCHEMA = """
Tables:
users(id, name, email, created_at)
orders(id, user_id, total_amount, created_at)
order_items(id, order_id, product_name, quantity, price)
Relations:
orders.user_id -> users.id
order_items.order_id -> orders.id
"""
def generate_sql(user_question):
prompt = f"""You are an expert SQL assistant.
Schema: {DB_SCHEMA}
Rules: SQLServer only, no explanations, no placeholders.
User: "{user_question}" """
resp = client.chat.completions.create(
model="gpt-4.1-mini",
messages=[
{"role": "system", "content": "Translate natural language to SQL."},
{"role": "user", "content": prompt}
],
temperature=0
)
return resp.choices[0].message.content
print(generate_sql("Show total revenue per user for last 30 days"))
Sjajno, ali… Ovo košta. I sporo je. I halucinira.
Opcija 3: Treniraćemo svoj LLM model
Ovo sam ja izabrao, delovalo je kao savršena priča. Završilo se kao programerska Twilight saga.
Rezultat? Četiri meseca rovovske borbe, kreiranja i čišćenja dataset-a što ručno što kroz skripting… i na kraju model koji je razumeo upite kad je on hteo. Model je čas radio, čas je halucinirao SQL kao da je upisao doktorski rad iz psihodeličnih nauka. Odoše četiri meseca kao Velikogradiškom košavom odneseni.
I tu negde, na ivici odustajanja i još jednog treninga modela, shvatio sam da LLM ne sme da odlučuje. LLM treba da pomaže.
Kako sam odustao od AI mađije i napravio sistem
Stanje u industriji je takvo da svi jure game-changer, a zapravo im treba useful-changer.
Suština je bila jednostavna: Većina pitanja koje korisnik postavi su predvidivi šabloni. Prepoznavanje šablona je moguće uz hibridni pristup u 5 koraka:
- Generisati šablone kao obrasce (templejte)
- Koristeći se embeddings-ima, ugraditi tekst iz obrazaca u vektore
- Pronaći tačan obrazac za postavljeno pitanje
- Popunjavanje parametara
- Izvršiti naredbu, tj. ili odgovoriti ili uraditi (SQL ili API)
Hajde da objasnimo detaljnije kako ovo radi:
Korak 1: Obrasci su dobri policajci
Da biste razumeli kako sistem uopšte funkcioniše, prvo pogledajte kako izgleda jedan obrazac (templejt):
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
{
"sql_id": "top_customers_by_revenue",
"intent": "Find top customers by revenue",
"template": "SELECT customer_name, SUM(revenue) as total FROM sales WHERE date >= DATEADD(day, -{days_back}, GETDATE()) GROUP BY customer_name ORDER BY total DESC LIMIT {limit}",
"params": {
"days_back": {"type": "integer", "default": 30},
"limit": {"type": "integer", "default": 10}
},
"nlu": {
"paraphrases": [
"top customers by revenue",
"best customers by sales",
"highest revenue clients",
"who are my biggest customers"
],
"entity_mappings": {
"days_back": {"last month": 30, "last quarter": 90},
"limit": {"top 5": 5, "top 10": 10, "last 10": 10, "top 20": 20}
}
}
}
Primećujete nešto? SQL se nikada ne menja. Menjaju se samo parametri. days_back i limit. Ovo je bitno jer:
- Možete da testirate SQL samo jednom i radiće uvek
- Može da se optimizuje tj. indeksira, kešira
- Ne halucinira, jeej
- Otkrivanje grešaka podrazumeva da pronađete obrazac, a ne “šta je sada model halucinirao”
Korak 2: Ugradnja teksta u vektore
Umesto da upoređujemo dva teksta na osnovu ključnih reči, želimo da ih uporedimo po tome šta zapravo znače. Svaki tekst i njegove parafraze dobijaju svoju vektorsku reprezentaciju, i kao takvi se ugrađuju u .pkl (pickle) fajl (hvala biblioteci text-embedding-3-large). Nakon generisanja vektora, provera je spremna.
Korak 3: Pronalazak pravog odgovora
Kada korisnik postavi pitanje, dešava se sledeće:
- Pretvori pitanje u vektor
pklfajl (računanje vektora - jedan API poziv, ~$0.00013 za 1k tokena) - Izračunava sličnost između vektora postavljenog pitanja i svih ostalih (vraća [-1,1] koristeći kosinus funkciju ugla)
- Vraća vektor koji je najbliži korisničkom pitanju po sličnosti. (Zavisi od postavljene granice sličnosti - koristio sam 0.65)
Zašto embeddings?
Prednost vektora i embeddings biblioteke je ta što kada korisnik napiše “najveći klijenti po prodaji” i “pokaži mi top kupce”, ove dve rečenice u vektorskom prostoru su praktično komšije, iako nemaju ni jednu jedinu zajedničku reč. Drugim rečima, posmatra se njihovo semantičko značenje.
To je ono što klasični rules engine nikada neće postići.
Korak 4: Popunjavanje parametara (Named Entity Recognition - NER)
Kada imamo spremni obrazac, preostaje nam da popunimo parametre. Koristio sam tri nivoa popunjavanja, uvek istim redom:
Nivo 1: Jednostavno mapiranje (70% slučajeva)
Pronalazi direktne fraze iz entity_mappings polja za svaki parametar. Tako da kada korisnik pošalje “List me top 10 customers last month” dobijamo:
- “last month” →
days_back = 30 - “top 10” →
limit = 10 - “last 10” →
limit = 10
Nivo 2: LLM ekstrakcija (+25% slučajeva)
- Kada Nivo 1 ne uspe, LLM dobija zadatak:
1 2 3 4 5
user_query = "list top 42 customers by revenue" prompt = f""" Extract days_back from: "{user_query}" Return JSON only: {"limit": <number>} """
- LLM odgovara
{"limit": 42}
Nivo 3: Predefinisane vrednosti (preostalih 5%)
- Ukoliko korisnik pita nešto poput “List most important customers”
- Ako ništa nije pronađeno, koriste se default vrednosti iz obrasca.
days_back = 30ilimit = 10
Korak 5: Ili odgovoriti ili uraditi
Jednu stvar volim da naglasim kod virtuelnih asistenata - nije sve SELECT. Asistent mora da zna šta da radi ukoliko dobije:
- “Napravi ponudu za NBGD D.O.O”
- “Pošalji informacije o ovoj ponudi na mejl Petru Petroviću iz firme NBGD D.O.O”
- “Dodaj proizvod Knjiga iz opštenarodne ribologije u ponudu #123”
Ovo nikako ne sme da ode u SQL deo programa. Ovo treba da predstavlja akcije koje okidaju u pozadini REST API pozive. Sistem proverava prvo akcije, pa ukoliko ne pronađe akciju, proverava SQL obrasce. Ovo je neophodno jer ne želimo da unos “Napravi novu ponudu” pokrene logiku za “Pokaži mi sve ponude”.
Ukoliko korisnik okine SQL deo programa, validacija je nužna. Ona obezbeđuje da sistem samo čita podatke iz baze podataka. Ukoliko se javi bilo koja “rizična” reč (DROP, DELETE, INSERT, UPDATE, TRUNCATE, ALTER) dalja radnja se automatski obustavlja.
Bez obzira da li podaci dolaze iz baze ili putem API poziva, pre nego što budu prikazani korisniku, prolaze kroz dodatnu obradu i formatiranje uz pomoć LLM-a radi jasnijeg i preglednijeg odgovora.
Zašto je ovo dobar pristup za produkciju?
Istraživanja pokazuju da generativni modeli često prave semantičke greške1, što potvrđuje važnost šablona kao stabilnog sloja. U poređenju s tim, čisto LLM rešenje sporije je, skuplje i sklonije halucinacijama, dok čisto rule-based rešenje brzo postane neodrživo.
Zato hibrid (šabloni + embeddings + mali LLM) pruža najbolji balans brzine, pouzdanosti i cene23.
Održavanje: Dodavanje novog templejta traje 10 minuta, dok rešavanje greške kada LLM halucinira traje 2 sata.
Trik sa embedding kešom
Pro-tip: keširajte vektore za instant učitavanje.
1
2
3
if os.path.exists("embeddings-file.pkl"):
with open("embeddings-file.pkl", 'rb') as f:
self.template_embeddings = pickle.load(f)
Ovako generišete vektor samo za korisničko pitanje tokom rada programa. Sve ostalo je već izračunato.
Preporuka za budućnost: Templejti koji uče?
Trenutno, templejti su ručno napisani, ali šta ukoliko bi mogli da uče iz korisničkih pitanja?
Posmatrajte šta korisnici pišu. Da li ste videli isto pitanje 10 puta? Generišite obrazac. Neka LLM generiše SQL kod, vi ga proverite, dodajte parametre i JSON obrazac je spreman.
Zaključak
Ako iz ovog teksta treba da ostane jedna misao, neka bude ova:
Ne morate da birate između pravila i AI-ja. Koristite pravila gde su jaka (strukturisani podaci, validacija), AI gde je jak (semantičko značenje, NER) i dobićete sistem koji radi na produkciji, sa stvarnim korisnicima, odlučuje na osnovu pravih podataka, ne halucinira. I sve to po ceni od $0.002 po upitu umesto $0.05.
Moj hibridni pristup nije privlačan, neće biti hot-topic na LinkedIn-u. Ne koristi najskuplje modele. Koristi embeddings iz 2023. godine, templejte iz 1990-ih i LLM-ove samo po potrebi.
Ali radi.
Ne pravim sisteme da budu magični, pravim ih da rade.
Ako želite da napravite sličan sistem, javite se mejlom: nikola@goluxai.com. Poslaću vam kod, objasniti principe i najvažnije - pomoći da zaobiđete moje greške.
Vidimo se u narednom članku, gde ulazimo u Akcije i REST API da bih objasnio kako virtualni asistent zna šta da uradi, a ne samo da odgovori.
Reference
- SEED Github
- LinkAlign: Scalable Schema Linking for Real-World Large-Scale Multi-Database Text-to-SQL
- SEED: Enhancing Text-to-SQL Performance and Practical Usability Through Automatic Evidence Generation
- RSL-SQL: Robust Schema Linking in Text-to-SQL Generation
- Getting AI to write good SQL: Text-to-SQL techniques explained
- ReFoRCE: A Text-to-SQL Agent with Self-Refinement, Consensus Enforcement, and Column Exploration